Can Big Data Guide Prognosis and Clinical Decisions in Epilepsy?
February 3, 2021
Abstract, originally published in Epilepsia
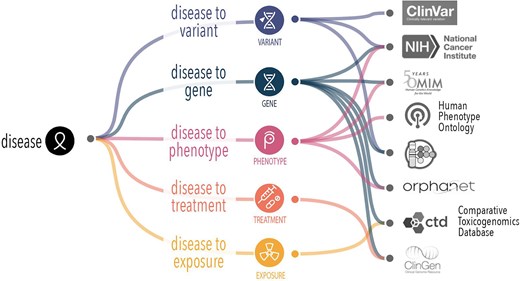
Big Data is no longer a novel concept in health care. Its promise of positive impact is not only undiminished, but daily enhanced by seemingly endless possibilities. Epilepsy is a disorder with wide heterogeneity in both clinical and research domains, and thus lends itself to Big Data concepts and techniques. It is therefore inevitable that Big Data will enable multimodal research, integrating various aspects of “-omics” domains, such as phenome, genome, microbiome, metabolome, and proteome.
This scope and granularity have the potential to change our understanding of prognosis and mortality in epilepsy. The scale of new discovery is unprecedented due to the possibilities promised by advances in machine learning, in particular deep learning. The subsequent possibilities of personalized patient care through clinical decision support systems that are evidence-based, adaptive, and iterative seem to be within reach.
A major objective is not only to inform decision-making, but also to reduce uncertainty in outcomes. Although the adoption of electronic health record (EHR) systems is near universal in the United States, for example, advanced clinical decision support in or ancillary to EHRs remains sporadic. In this review, we discuss the role of Big Data in the development of clinical decision support systems for epilepsy care, prognostication, and discovery.
Latest from the Community